A. Découverte et établissement du code génétique
L'alphabet de l'ADN est constitué de quatre lettres (quatre bases azotées différentes : A-adénine, T-thymine, C-cytosine, G-guanine) tandis que celui des protéines est constitué de vingt acides aminés différents. Il est donc impossible qu'un nucléotide correspond à un seul acide aminé.
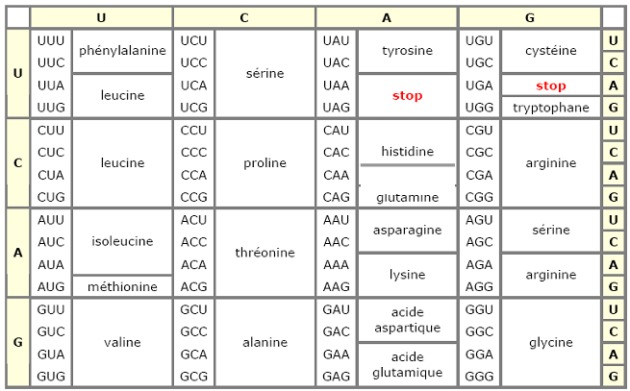
Ainsi, il a été admis qu'un acide aminé de la séquence des protéines est codé par la combinaison d'un triplet de base azotée de la séquence de l'ADN.
L'approche expérimentale de décryptage et de l'établissement du code génétique a été réalisée par Niremberg et Khorana vers 1965. Pour ce faire, ils ont mis en présence un acide nucléique de séquence connue, répétitive et constitué de l'alternance de seulement deux bases, avec des acides aminés libres dans un milieu permettant la production de protéines. La séquence en acides aminés des protéines ainsi produites a pu être comparée à la séquence connue des acides nucléiques de départ. En réalisant l'expérience avec d'autres séquences d'acides nucléiques du même type, ils ont pu établir un tableau de correspondance entre des groupes de trois nucléotides (= codons) et les vingt acides aminés constituants des protéines.
Le code génétique donne donc la correspondance entre un codon porté par l'ARN messager et un acide aminé. Ainsi, la modification seulement d'une base azotée le long de la séquence d'acide nucléique qui constitue l'information génétique d'un individu suffit à modifier la séquence de la protéine qui en est issue.